Un sistema que aprovecha modelos de difusión de texto a imagen previamente entrenados para usarlos en restauración de imágenes.*ColabPro https://colab.research.google.com/github/camenduru/DiffBIR-colab/blob/main/DiffBIR_colab.ipynb *Github https://github.com/XPixelGroup/DiffBIR *Paper https://arxiv.org/abs/2308.15070
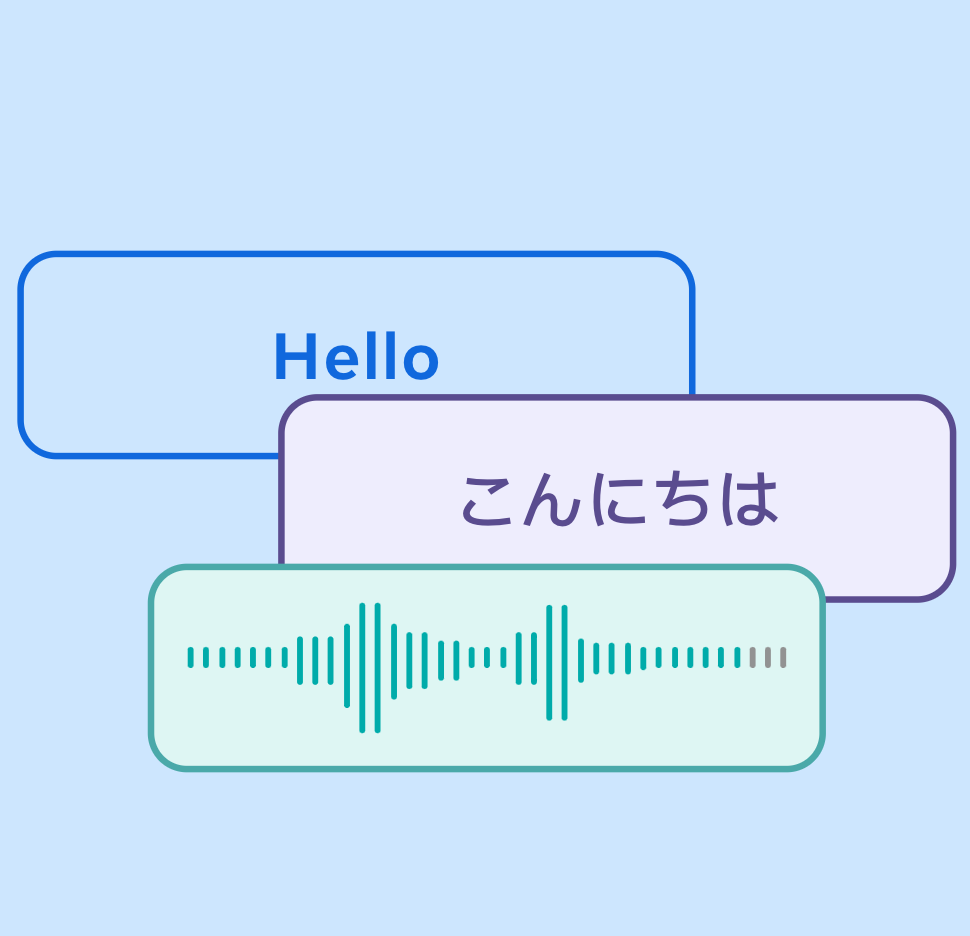
Un traductor universal, está diseñado para proporcionar traducción de alta calidad, permitiendo que personas de diferentes comunidades lingüísticas se comuniquen sin esfuerzo a través de voz y texto. *Web https://github.com/facebookresearch/seamless_communication *Colab https://colab.research.google.com/github/camenduru/seamless-m4t-colab/blob/main/seamless_m4t_colab.ipynb *Demo https://seamless.metademolab.com/ *HuggingFace https://huggingface.co/spaces/facebook/seamless_m4t *Github https://github.com/facebookresearch/seamless_communication *Papper https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf
Magenta: Una herramienta que utiliza el aprendizaje automático para ayudar en el proceso creativo de arte y música.
Magenta es un proyecto de código abierto que explora el papel del aprendizaje automático como herramienta en el proceso creativo. Ofrece una colección de herramientas de creatividad musical basadas en modelos de código abierto, utilizando técnicas avanzadas de aprendizaje automático para la generación de música.*Web https://magenta.tensorflow.org/ *Demo https://magenta.tensorflow.org/demos *Ableton https://magenta.tensorflow.org/studio *JS https://github.com/magenta/magenta-js *Github https://github.com/magenta *Manual https://magenta.tensorflow.org/studio#:~:text=Studio%20v1.0.-,TABLE%20OF%20CONTENTS,-Overview
Music To Image: Una herramienta que convierte tu música en imágenes únicas
"Music To Image", desarrollada por "fffiloni", tiene la capacidad de convertir música en imágenes, permitiendo a los usuarios visualizar música de una manera nueva y creativa. Genera imágenes únicas basadas en las características de la música ingresada, ofreciendo una experiencia visual innovadora que complementa la música.*Web https://huggingface.co/spaces/fffiloni/Music-To-Image
TokenFlow: Edita tus videos con indicaciones de texto
A partir de un video de entrada y una indicacion de texto, podras editar el estilo, los objetos o los personajes en tu video.*Demo https://huggingface.co/spaces/weizmannscience/tokenflow *Web https://diffusion-tokenflow.github.io/ *Github https://github.com/omerbt/TokenFlow *Paper https://arxiv.org/abs/2307.10373
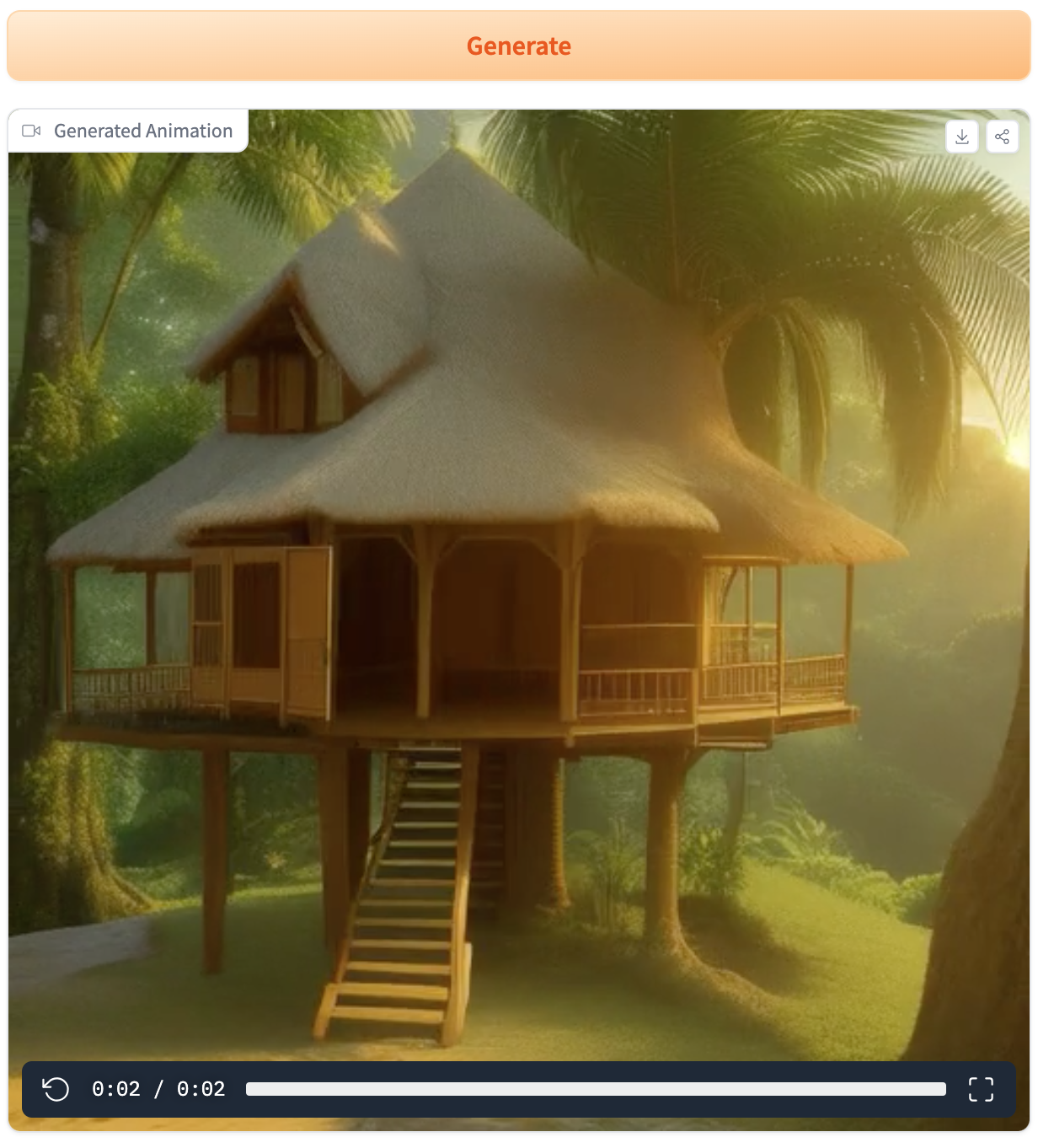
AnimateDiff: Cree una imagen animada a partir de una indicacion de texto
Este sistema proporciona una técnica para crear una secuencia de imágenes coherente en el tiempo para obtener una animación a partir de la descripción de una imagen.*Demo https://huggingface.co/spaces/guoyww/AnimateDiff *Web https://animatediff.github.io/ *Github https://github.com/guoyww/animatediff/ *Paper https://arxiv.org/abs/2307.04725
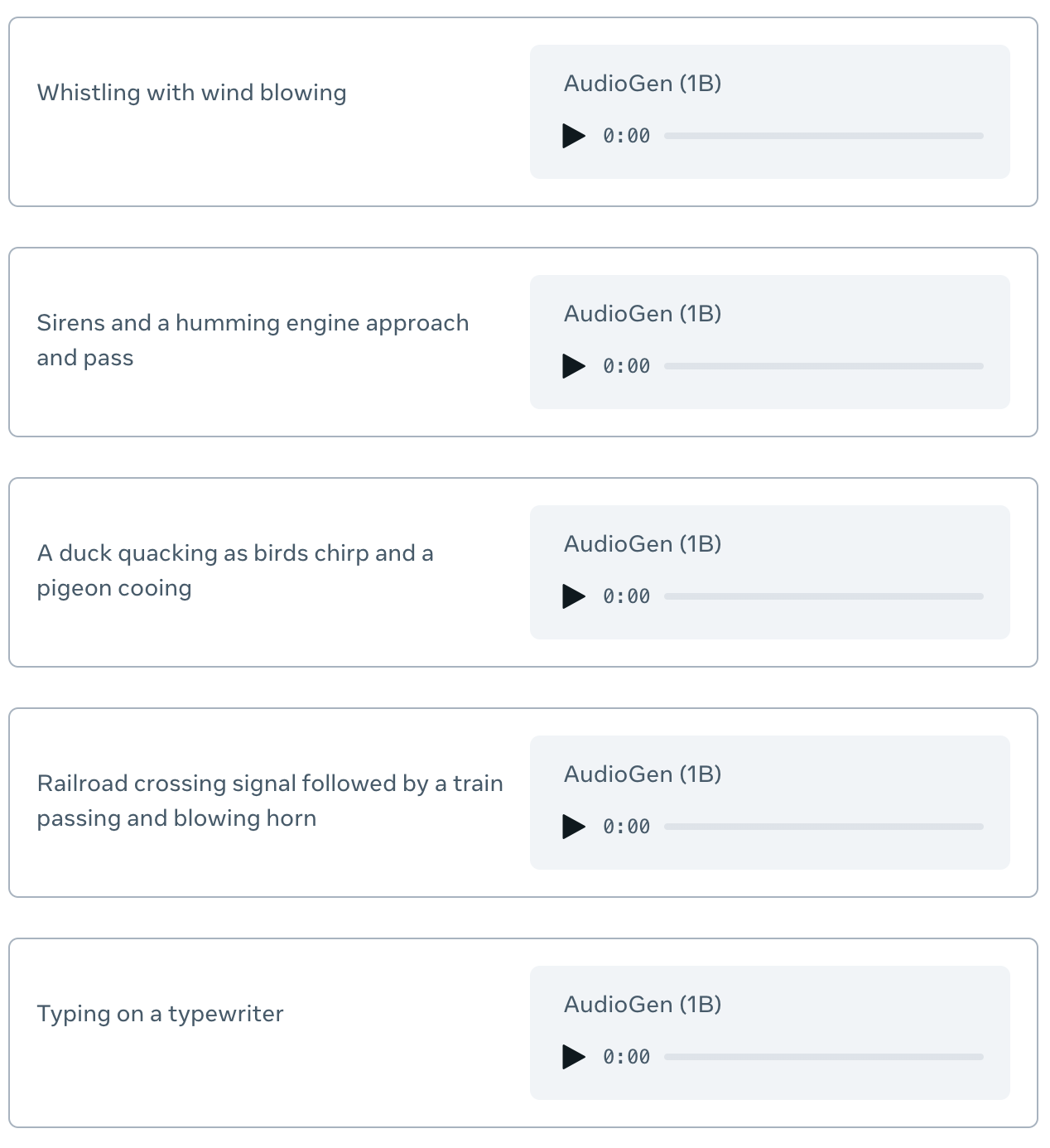
AudioGen – Genera efectos de audio a partir de indicaciones de texto
AudioGen es un modelo de conversión de texto a sonido, creado a partir de Audiocraft, una librería de pytorch de Meta para investigaciones de aprendizaje profundo sobre generación de audio. *Web https://audiocraft.metademolab.com/audiogen.html *Colab https://colab.research.google.com/github/camenduru/audiogen-colab/blob/main/audiogen_colab.ipynb *Github https://github.com/facebookresearch/audiocraft/blob/main/docs/AUDIOGEN.md *Paper https://arxiv.org/abs/2209.15352
Pix2Pix Video: Edición de estilo de video, guiado por texto
Una implementación de Pix2Pix aplicado a una secuencia de imágenes, que puedes utilizar en tus propios videos. Al ser un proceso que se aplica a cada imagen independiente, el vídeo resultante muestra saltos en el estilo, aunque mantiene la morfología de la imagen entrante. *Demo https://huggingface.co/spaces/fffiloni/Pix2Pix-Video*Colab https://colab.research.google.com/github/camenduru/pix2pix-video-colab/blob/main/pix2pix-video-colab.ipynb#scrollTo=Cp1aDyeElG57 *Code https://huggingface.co/spaces/fffiloni/Pix2Pix-Video/blob/main/app.py
Word-As-Image for Semantic Typography: Generador de tipografía semántica
Un sistema que crea una fuente con un estilo gráfico asociado al concepto de las palabras que se escriben con ella.*Web: https://wordasimage.github.io/Word-As-Image-Page/*Demo: https://huggingface.co/spaces/SemanticTypography/Word-As-Image*Github: https://github.com/Shiriluz/Word-As-Image*Paper: https://arxiv.org/abs/2303.01818
ControlNet: De un boceto a una imagen
Un sistema que permite usar condiciones de entrada adicionales para los modelos de generación de imágenes por difusión, permitiendo que podamos generar imágenes a partir de bocetos, datos de profundidad u otras imágenes junto a una frase de descripción. *Colab https://colab.research.google.com/drive/1VRrDqT6xeETfMsfqYuCGhwdxcC2kLd2P?usp=sharing *Github https://github.com/lllyasviel/ControlNet *Paper https://arxiv.org/abs/2302.05543
BLIP-2: Chat con texto e imagen
Un sistema que permite tener conversaciones a partir del contenido de una imagen. *Colab https://colab.research.google.com/github/salesforce/LAVIS/blob/main/projects/img2prompt-vqa/img2prompt_vqa.ipynb#scrollTo=7428ac2d *Github https://github.com/salesforce/LAVIS *Paper https://arxiv.org/abs/2301.12597
Hyperreel: Reproductor de vídeos 6DOF
Una forma de reproducir de forma optimizada, videos de 6 grados de libertad, es decir, videos en los que puedes moverte por la escena en su espacio tridimensional. *Web https://hyperreel.github.io/ *Github https://github.com/facebookresearch/hyperreel *Paper https://arxiv.org/abs/2301.02238
Arcane, Disney y Archer: Caricaturizador con estilos
Consiste en el generador de imágenes stable diffusion entrenado con tres estilos específicos a partir del método Dreambooth. *Demo https://huggingface.co/nitrosocke/Nitro-Diffusion
Plug-and-Play Diffusion: Edición de imagen a imagen basada en texto
Una alternativa más a realizar esta tarea, consiste en una implementación basada en stable_diffusion que modifica el aspecto de una imagen a partir de indicaciones de texto, manteniendo su estructura original. Funciona, haciendo una reconstrucción sintética de la imagen original, estableciendo la descripción de sus componentes para después modificar dichos componentes de forma independiente de acuerdo al input de texto. *Web https://pnp-diffusion.github.io/ *Demo https://huggingface.co/spaces/hysts/PnP-diffusion-features *Github https://github.com/MichalGeyer/plug-and-play *Paper https://arxiv.org/abs/2211.12572
instruct pix2pix: Editar imágenes a partir de texto
Consiste en una implementación basada en stable_diffusion que modifica el aspecto de una imagen a partir de indicaciones de texto, manteniendo su estructura original. *Web https://www.timothybrooks.com/instruct-pix2pix/ *Demo https://huggingface.co/spaces/timbrooks/instruct-pix2pix *HuggingFace https://huggingface.co/timbrooks/instruct-pix2pix *Github https://github.com/timothybrooks/instruct-pix2pix *Paper https://arxiv.org/abs/2211.09800
3d diffusion: Generación de modelo 3D a partir de una sola imagen
Este modelo sintetiza una modelo 3D a partir de la predicción de múltiples fiestas de una sola perspectiva dada por una imagen. *Web https://3d-diffusion.github.io/ *Paper https://arxiv.org/abs/2210.04628
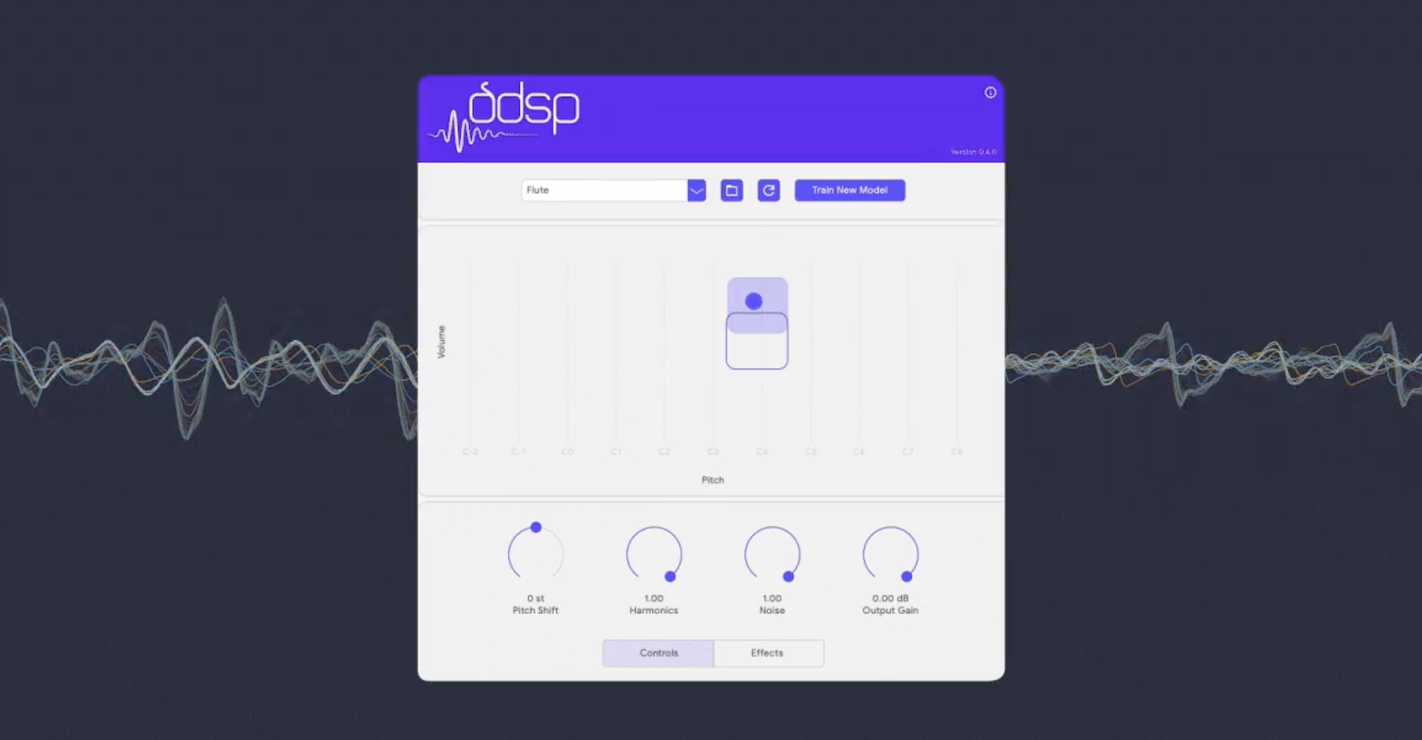
DDSP-VST: Herramienta de síntesis neural que transforma y enriquece tu proceso creativo con sonidos innovadores
DDSP-VST es una herramienta que permite experimentar con nuevos sonidos y transformar tu proceso creativo. Puedes utilizarlo como un instrumento virtual típico, integrándolo en tu flujo de trabajo con tus fuentes y efectos MIDI favoritos. Además, ofrece controles para ajustar el tono y obtener sonidos realistas o explorar una amplia gama de timbres que se desvían del sonido original. También puedes crear tus propios modelos con su entrenador web gratuito, lo que permite personalizar aún más tu experiencia sonora.*Web https://magenta.tensorflow.org/ddsp-vst
Stable diffusion: Texto a imagen
Un generador texto a imágen Open Source y pre-entrenado, uno de los sistemas que más causó revuelo en el 2022 por su carácter libre, al haber sido liberado junto a sus pesos de entrenamiento listo para usar. *Demo https://huggingface.co/spaces/stabilityai/stable-diffusion *Demo Pago https://beta.dreamstudio.ai/dream *Colab https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb *Mac https://diffusionbee.com/ *Pc https://nmkd.itch.io/t2i-gui *Web https://stability.ai/blog/stable-diffusion-public-release