Technique pour maintenir un style cohérent et réduire le scintillement dans une animation générée par l'IA. *Github https://github.com/Sxela/DiscoDiffusion-Warp*Colab https://colab.research.google.com/drive/15D2WIF_vE2l48ddxEx45cM3RykZwQXM8?usp=sharing
SRT – Scene Representation Transformer: Synthèse d’une scène 3D complète
À partir de quelques images, ce système reconstruit une scène en temps réel, en "hallucinant" les parties de la scène qu'il ne connaît pas afin de lui donner de la cohérence. *Web https://srt-paper.github.io/*Colab https://colab.research.google.com/github/srt-paper/srt-paper.github.io/blob/main/multi_shapenet.ipynb*Github https://github.com/stelzner/srt*Paper https://arxiv.org/abs/2111.13152
Dream Fields: Du texte au 3D
Dreamfields, un système qui crée des modèles 3D à partir de textes. *Colab: https://colab.research.google.com/drive/1TjCWS2_Q0HJKdi9wA2OSY7avmFUQYGje?usp=sharing*Web https://ajayj.com/dreamfields*Github https://github.com/google-research/google-research/tree/master/dreamfields*Paper https://arxiv.org/abs/2112.01455
VGPNN: Generación y manipulación de video
Una herramienta que permite la manipulación de video (Extensión temporal, resumen, redimensionamiento, aplicación de estilo entre otros) sin el uso de deep learning, si no con un enfoque más clásico basado en Granot et al. (2021) permitiendo procesamientos sustancialmente rápidos. * Web https://nivha.github.io/vgpnn/ *github https://github.com/nivha/single_video_generation *paper https://arxiv.org/abs/2109.08591
Spleeter4Max : Un outil pour séparer les pistes audio dans Ableton en utilisant Spleeter
Spleeter4Max est un outil qui permet de séparer les pistes audio dans Ableton en utilisant Spleeter, facilitant ainsi le processus de décomposition des chansons en différents éléments tels que les voix et les instruments.*Ableton https://github.com/diracdeltas/spleeter4max/releases *Max https://github.com/diracdeltas/spleeter4max/tree/feature/native-spleeter#spleeter-for-max-native-version *Tutorial https://www.youtube.com/watch?v=4pcJoI5CUOA
Time-Travel Rephotography: Restauration de portraits
Une méthode de restauration des portraits anciens ne consiste pas seulement en une colorisation, mais en une restructuration complète de la photographie pour la reconstruire comme si elle avait été prise par un appareil photo moderne. Cette méthode consiste à transporter l'image dans l'espace d'un StyleGAN2 entraîné avec des portraits modernes à haute résolution, en réalisant simultanément le débruitage, la colorisation et la super-résolution.*Web https://time-travel-rephotography.github.io/*Colab https://colab.research.google.com/drive/15D2WIF_vE2l48ddxEx45cM3RykZwQXM8?usp=sharing*Paper https://arxiv.org/pdf/2012.12261.pdf
InstColorization: Colorisation d’images
Colorisation d'images avec reconnaissance d'instances, c'est-à-dire un système d'IA qui colore des images en noir et blanc après avoir identifié les objets présents dans l'image, afin de la coloriser partie par partie. *Web https://wandb.ai/wandb/instacolorization/reports/Overview-Instance-Aware-Image-Colorization---VmlldzoyOTk3MDI *Colab https://colab.research.google.com/github/ericsujw/InstColorization/blob/master/InstColorization.ipynb *Github https://github.com/ericsujw/InstColorization *Paper https://cgv.cs.nthu.edu.tw/InstColorization_data/InstaColorization.pdf
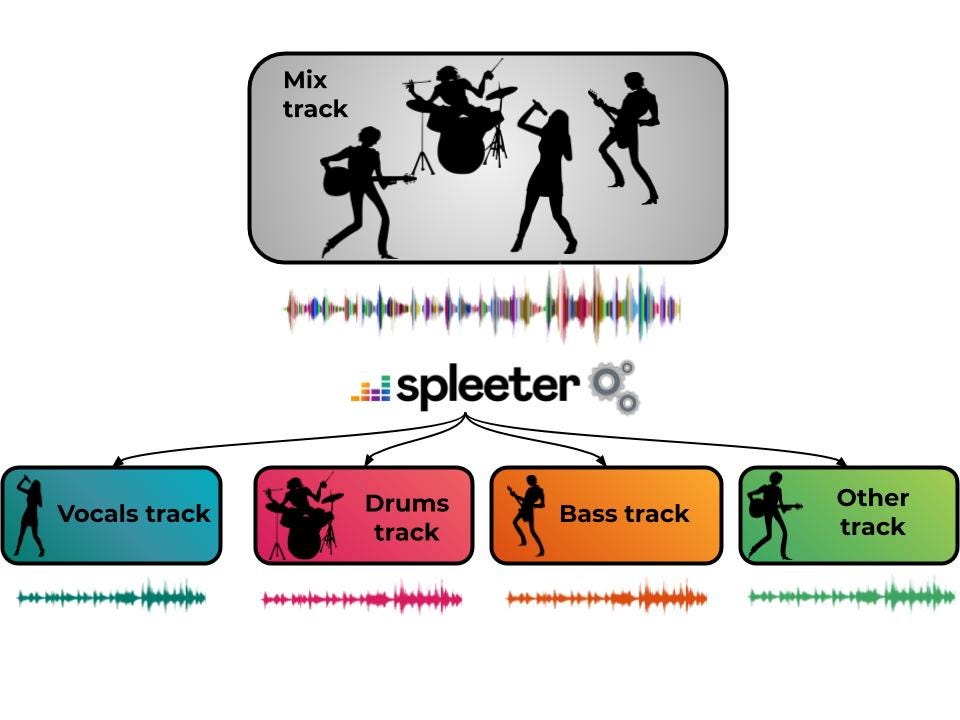
Spleeter de Deezer : Une bibliothèque pour la séparation des sources audio avec des modèles pré-entraînés
Spleeter est une bibliothèque de séparation des sources audio développée par Deezer qui inclut des modèles pré-entraînés. Écrit en Python et utilisant TensorFlow, il facilite la séparation des pistes audio en différents composants, tels que les voix, la batterie, la basse, entre autres, avec une grande vitesse de traitement, notamment sur un GPU. Il peut être utilisé directement depuis la ligne de commande ou intégré dans des pipelines de développement en tant que bibliothèque Python.*Web https://pypi.org/project/spleeter/ *Colab https://colab.research.google.com/github/deezer/spleeter/blob/master/spleeter.ipynb *Manual https://github.com/deezer/spleeter/wiki *Github https://github.com/deezer/spleeter
MuseNet: Un réseau neuronal profond qui génère des compositions musicales avec différents instruments et styles.
MuseNet est un réseau neuronal profond développé par OpenAI qui peut générer des compositions musicales de 4 minutes avec jusqu'à 10 instruments différents, combinant des styles allant du country à Mozart ou The Beatles. MuseNet n'a pas été programmé explicitement avec une compréhension de la musique, mais a découvert des motifs d'harmonie, de rythme et de style en apprenant à prédire le token suivant dans des centaines de milliers de fichiers MIDI. Il utilise une technologie non supervisée générale similaire à GPT-2. *Web https://openai.com/research/musenet *Colab https://colab.research.google.com/github/asigalov61/OpenAI-MuseNet-Colab-Notebook/blob/main/OpenAI_MuseNet_Colab_Notebook.ipynb
MediaPipe Hands: Suivi de la pose des mains en temps réel et multiplateforme
MediaPipe Hands est une solution de suivi des mains et des doigts de haute fidélité. Elle utilise l'apprentissage automatique pour déduire 21 points 3D d'une main à partir d'une seule image. Elle permet d'obtenir des performances en temps réel sur un téléphone mobile et même sur le web pour plusieurs mains. * Web https://google.github.io/mediapipe/solutions/hands *Demo https://rdtr01.xl.digital/ *Demo+Codigo https://codepen.io/mediapipe/pen/RwGWYJw *Github https://github.com/google/mediapipe
WaveNet : Un modèle génératif pour l’audio brut
WaveNet est un modèle génératif profond capable de créer des ondes audio brutes, capable de générer un discours qui imite n'importe quelle voix humaine, sonnant plus naturel que les systèmes de texte à la parole existants (2016). De plus, il peut synthétiser d'autres types de signaux audio, comme la musique, générant automatiquement des morceaux de piano avec des résultats surprenants.*Web https://www.deepmind.com/research/highlighted-research/wavenet *Demo https://play.ht/text-to-speech-voices/google-wavenet/ *Colab https://colab.research.google.com/github/olaviinha/WaveNet/blob/master/WaveNet.ipynb#scrollTo=Zidq9-vvLF7l *Github https://github.com/ibab/tensorflow-wavenet