Un système qui exploite des modèles de diffusion texte-image préalablement formés pour la restauration d'images.*ColabPro https://colab.research.google.com/github/camenduru/DiffBIR-colab/blob/main/DiffBIR_colab.ipynb *Github https://github.com/XPixelGroup/DiffBIR *Paper https://arxiv.org/abs/2308.15070
Un traducteur universel. Il est conçu pour fournir une traduction de haute qualité, permettant à des personnes issues de communautés linguistiques différentes de communiquer sans effort par la voix et le texte. *Web https://github.com/facebookresearch/seamless_communication *Colab https://colab.research.google.com/github/camenduru/seamless-m4t-colab/blob/main/seamless_m4t_colab.ipynb *Demo https://seamless.metademolab.com/ *HuggingFace https://huggingface.co/spaces/facebook/seamless_m4t *Github https://github.com/facebookresearch/seamless_communication *Papper https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf
Magenta: Un outil utilisant l’apprentissage automatique pour aider dans le processus créatif de l’art et de la musique.
Magenta est un projet open source qui explore le rôle de l'apprentissage automatique comme outil dans le processus créatif. Il propose une collection d'outils de créativité musicale basés sur des modèles open source, utilisant des techniques d'apprentissage automatique de pointe pour la génération de musique.*Web https://magenta.tensorflow.org/ *Demo https://magenta.tensorflow.org/demos *Ableton https://magenta.tensorflow.org/studio *JS https://github.com/magenta/magenta-js *Github https://github.com/magenta *Manual https://magenta.tensorflow.org/studio#:~:text=Studio%20v1.0.-,TABLE%20OF%20CONTENTS,-Overview
Music To Image: Un outil qui transforme votre musique en images uniques
"Music To Image", développée par "fffiloni", a la capacité de convertir la musique en images, permettant aux utilisateurs de visualiser la musique d'une manière nouvelle et créative. Il génère des images uniques basées sur les caractéristiques de la musique entrée, offrant une expérience visuelle innovante qui complète la musique.*Web https://huggingface.co/spaces/fffiloni/Music-To-Image
TokenFlow : Modifiez vos vidéos à partir des instructions du texte
À partir d'une vidéo d'entrée et d'une indication de texte, vous pouvez modifier le style, les objets ou les caractères de votre vidéo.*Demo https://huggingface.co/spaces/weizmannscience/tokenflow *Web https://diffusion-tokenflow.github.io/ *Github https://github.com/omerbt/TokenFlow *Paper https://arxiv.org/abs/2307.10373
AnimateDiff : Créer une image animée à partir d’une instruction de texte
Ce système propose une technique de création d'une séquence d'images cohérente dans le temps pour obtenir une animation à partir de la description d'une image.*Demo https://huggingface.co/spaces/guoyww/AnimateDiff *Web https://animatediff.github.io/ *Github https://github.com/guoyww/animatediff/ *Paper https://arxiv.org/abs/2307.04725
Word-As-Image for Semantic Typography: Générateur de typographie sémantique
Système qui crée une police de caractères dont le style graphique est associé au concept des mots qui sont écrits avec elle. *Web: https://wordasimage.github.io/Word-As-Image-Page/*Demo: https://huggingface.co/spaces/SemanticTypography/Word-As-Image*Github: https://github.com/Shiriluz/Word-As-Image*Paper: https://arxiv.org/abs/2303.01818
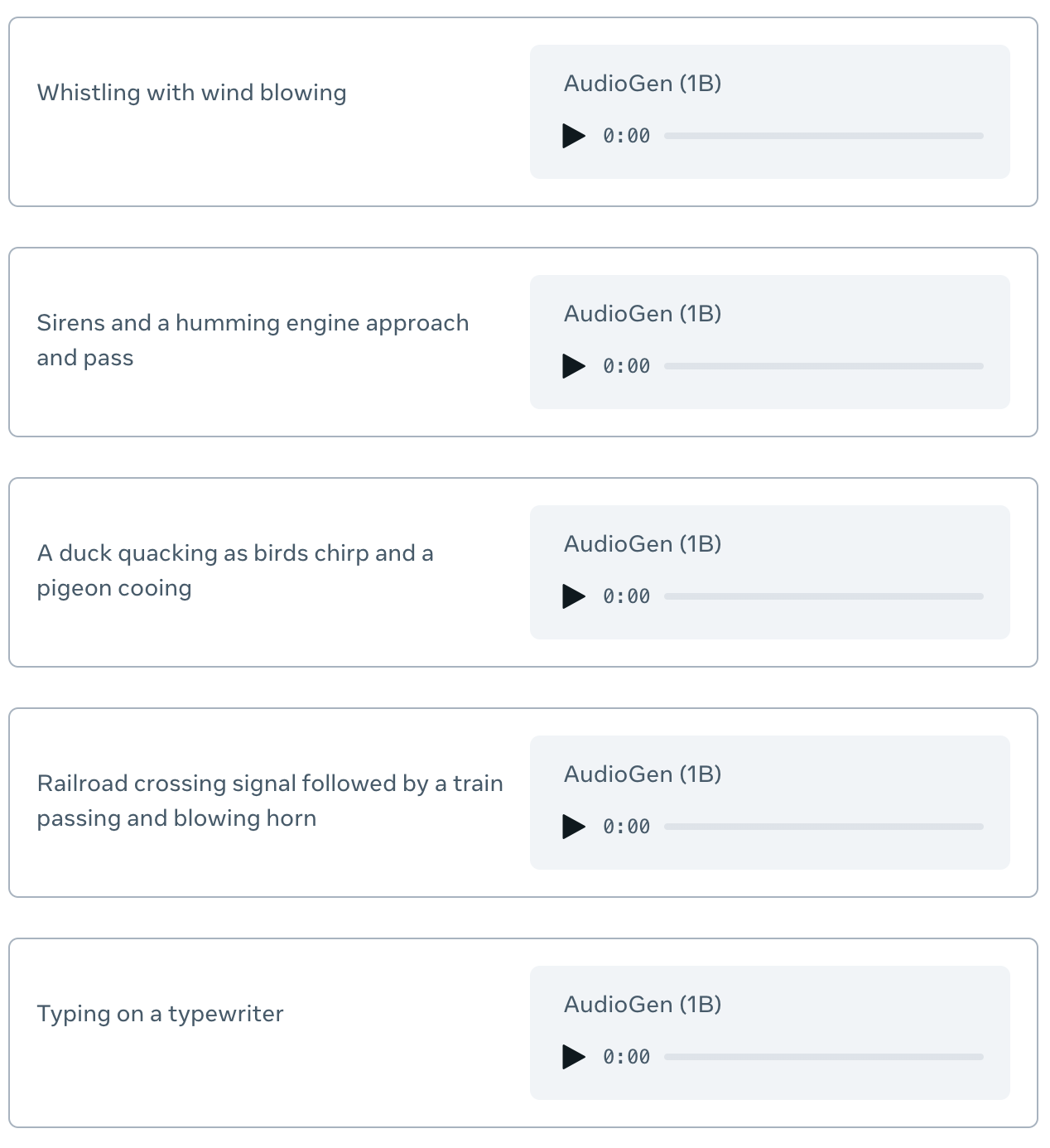
AudioGen – Générer des effets audio à partir de textes
Audiogen est un modèle pour la synthèse du son, créé à partir d'Audiocraft, une bibliothèque Meta pytorch pour la recherche sur l'apprentissage profond de la génération audio.*Web https://audiocraft.metademolab.com/audiogen.html *Colab https://colab.research.google.com/github/camenduru/audiogen-colab/blob/main/audiogen_colab.ipynb *Github https://github.com/facebookresearch/audiocraft/blob/main/docs/AUDIOGEN.md *Paper https://arxiv.org/abs/2209.15352
Pix2Pix Video: Edition de style vidéo guidée par texte
Une implémentation de Pix2Pix appliquée à une séquence d'images, que vous pouvez utiliser dans vos propres vidéos. Comme il s'agit d'un processus appliqué à chaque image indépendamment, la vidéo résultante présente des sauts de style, tout en conservant la morphologie de l'image entrante. *Demo https://huggingface.co/spaces/fffiloni/Pix2Pix-Video*Colab https://colab.research.google.com/github/camenduru/pix2pix-video-colab/blob/main/pix2pix-video-colab.ipynb#scrollTo=Cp1aDyeElG57 *Code https://huggingface.co/spaces/fffiloni/Pix2Pix-Video/blob/main/app.py
ControlNet: Du croquis à l’image
Un système qui permet d'utiliser des conditions d'entrée supplémentaires pour les modèles d'imagerie de diffusion, ce qui nous permet de générer des images à partir de croquis, de données de profondeur ou d'autres images accompagnées d'une phrase de description. *Colab https://colab.research.google.com/drive/1VRrDqT6xeETfMsfqYuCGhwdxcC2kLd2P?usp=sharing *Github https://github.com/lllyasviel/ControlNet *Paper https://arxiv.org/abs/2302.05543
BLIP-2: Chat texte et image
Un système qui permet d'avoir des conversations basées sur le contenu d'une image. *Colab https://colab.research.google.com/github/salesforce/LAVIS/blob/main/projects/img2prompt-vqa/img2prompt_vqa.ipynb#scrollTo=7428ac2d *Github https://github.com/salesforce/LAVIS *Paper https://arxiv.org/abs/2301.12597
Hyperreel: Lecteur vidéo 6DOF
Un moyen d'optimiser la lecture des vidéos à 6 degrés de liberté, c'est-à-dire des vidéos dans lesquelles vous pouvez vous déplacer autour de la scène dans son espace tridimensionnel. *Web https://hyperreel.github.io/ *Github https://github.com/facebookresearch/hyperreel *Paper https://arxiv.org/abs/2301.02238
Live 3D: Modélisation et animation de personnages de manga
Arcane, Disney et Archer: Caricaturiste avec styles
Il s'agit d'un imageur de diffusion stable formé à trois styles spécifiques de la méthode Dreambooth. *Demo https://huggingface.co/nitrosocke/Nitro-Diffusion
Plug-and-Play Diffusion: Édition d’image à image basée sur du texte
Une autre alternative à cette tâche est une implémentation basée sur la diffusion stable qui modifie l'apparence d'une image à partir d'invites textuelles tout en conservant sa structure originale. Elle fonctionne en faisant une reconstruction synthétique de l'image originale, en établissant la description de ses composants et en modifiant ensuite ces composants de manière indépendante en fonction de l'entrée textuelle. *Demo https://huggingface.co/spaces/hysts/PnP-diffusion-features *Github https://github.com/MichalGeyer/plug-and-play *Paper https://arxiv.org/abs/2211.12572
instruct pix2pix: Modifier des images à partir d’un texte
Il s'agit d'une implémentation basée sur stable_diffusion qui modifie l'apparence d'une image à partir d'invites textuelles tout en conservant sa structure d'origine. *Web https://www.timothybrooks.com/instruct-pix2pix/ *Demo https://huggingface.co/spaces/timbrooks/instruct-pix2pix *HuggingFace https://huggingface.co/timbrooks/instruct-pix2pix *Github https://github.com/timothybrooks/instruct-pix2pix *Paper https://arxiv.org/abs/2211.09800
3d diffusion: Génération de modèles 3D à partir d’une seule image
Ce modèle synthétise un modèle 3D à partir de la prédiction de plusieurs parties depuis une perspective unique donnée par une image. *Web https://3d-diffusion.github.io/ *Paper https://arxiv.org/abs/2210.04628
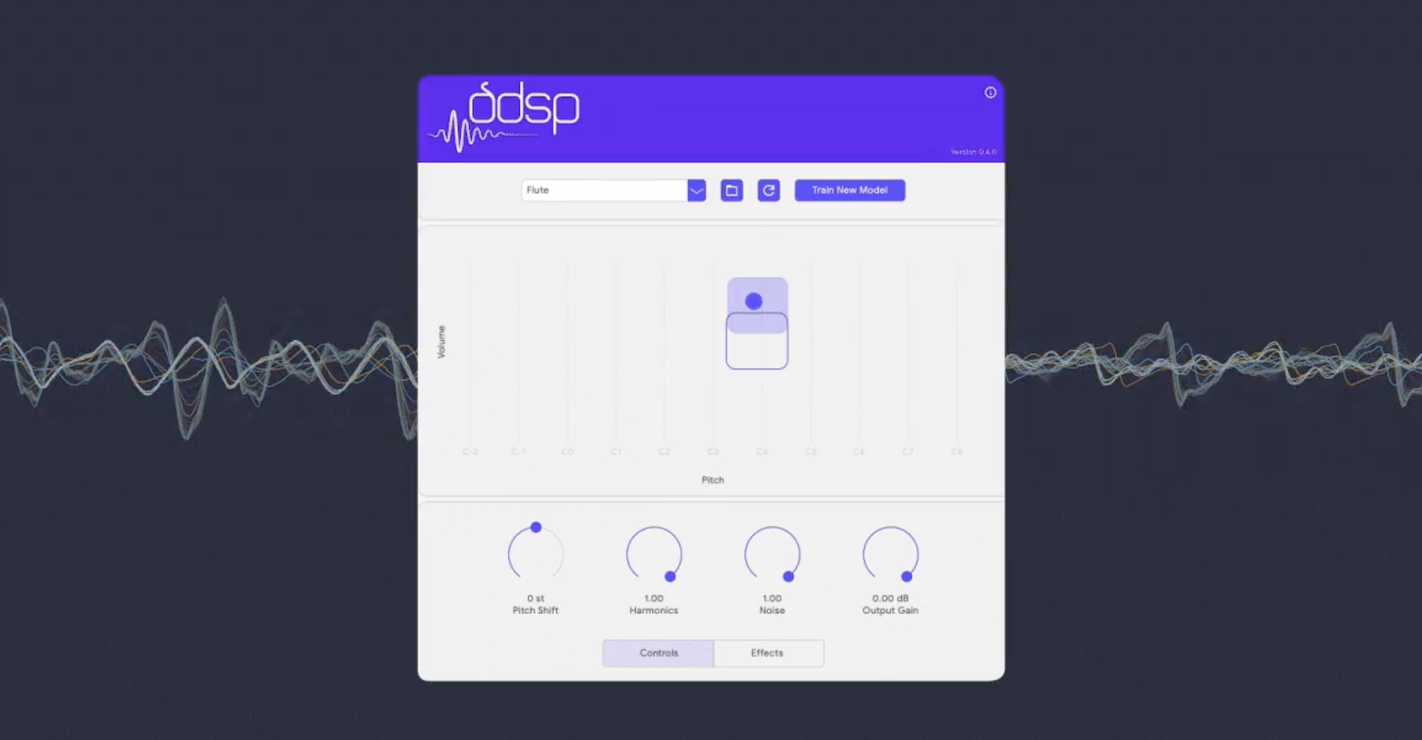
DDSP-VST: Outil de synthèse neurale qui transforme et enrichit votre processus créatif avec des sons innovants
DDSP-VST est un outil qui vous permet d'expérimenter avec de nouveaux sons et de transformer votre processus créatif. Vous pouvez l'utiliser comme un instrument virtuel typique, en l'intégrant dans votre flux de travail avec vos sources et effets MIDI préférés. De plus, il offre des contrôles pour ajuster le ton et obtenir des sons réalistes ou explorer une large gamme de timbres qui s'écartent du son original. Vous pouvez également créer vos propres modèles avec son entraîneur web gratuit, permettant une personnalisation encore plus grande de votre expérience sonore.*Web https://magenta.tensorflow.org/ddsp-vst
Stable diffusion: Du texte à l’image
Un générateur de texte-image pré-entraîné Open Source, l'un des systèmes qui a fait le plus de bruit en 2022 en raison de son caractère libre, a été publié avec ses poids d'entraînement prêts à l'emploi. *Demo https://huggingface.co/spaces/stabilityai/stable-diffusion *Demo Pago https://beta.dreamstudio.ai/dream *Colab https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb *Mac https://diffusionbee.com/ *Pc https://nmkd.itch.io/t2i-gui *Web https://stability.ai/blog/stable-diffusion-public-release